Summer Week 6: Hedgehogs - time of day, exploration of available space in ABM, data; TESSERA x Semantic embeddings
Categories:EnvironmentAI/ML🦔FoundationalML
This week
Over the first half of this week, I mostly continued expanding the hedgehog project. I finally got my hands on some long-awaited data, (hopefully) improved the statistical analysis of hedgehog movement, and also implemented a realistic selection of accessible space in the agent-based model. The rest of the week, I spent working with TESSERA, particularly exploring options for fusing my work on semantically-based geospatial embeddings with representations generated by the foundational model. I think this could be a really interesting direction, although I’m mostly trying to figure out where I could take it.
Hedgehogs
I solved the problem of including time-of-day (and subsequent variety of hedgehog ‘modes’) by just splitting the problem into four separate models, each representing a different time of day. In particular, the models separately covered 1am - 10am (past 5am is mostly sleep), 10am - 21 pm (most of this is sleep), 21pm - midnight, and midnight - 1am. This split was guided by a combination of prior expectations, but also, to some degree, data availability. Furthermore, the only way to avoid convergence and other issues was through uncompromising filtering of the covariates, causing issues (e.g., perfect separation). I guess this means that any coefficients extracted should be extended with some assumptions to broader categories of landscape features, but also that with more data, broader coverage could be obtained.
I also implemented a function for exploring the available space at each step in the agent-based model. I don’t think this is particularly important from the ‘large-scale point of view’, and it is quite slow, but it could be interesting if we were to measure the effect of gates or fence holes for hedgehogs somehow.
Lastly, the hedgerow & stonewall & woodland dataset was made fully available, including coverage for the particular area in which my hedgehog roam. This is quite helpful, and of very high quality, but it is also interesting to see overlaps and differences against my “bramble” mapping (from last week). Whereas the Deepmind dataset is strictly proper hedgerows, my brambles layer is a lot less obvious, hidden, obscured, or complementary bush vegetation. Nonetheless, I was just recently prompted to improve the bushes extraction, so maybe it will really be just brambles soon.
TESSERA x Urban Semantic Embeddings
This, so far, is only a very general direction, but the idea is to complement TESSERA with semantic embeddings generated from encoders such as the ones I have been using in my walkability work (or vice versa). I realized that I’m not exactly certain how this can be used, in particular for some kind of evaluation, but Professor Madhavapeddy clearly had some ideas.
So far, I have been mostly experimenting with finding ways to combine the two. I managed to run quite a few experiments, a few of which focused on getting nice visualizations (because that’s the best part). I have used mainly 768-dimensional embeddings generated by an all-mpnet-base-v2 encoder because it took me a while to retrieve embeddings generated by all-MiniLM-L12-v2, which are 384-dimensional, and, in my experience, generally produced better results. The fact that TESSERA’s embeddings are 128-dimensional is another reason why all-MiniLM-L12-v2 may be better for these experiments.
Regarding combining the two vector sets, one approach worth mentioning was downsizing the semantic embeddings to a 128-dimensional space with PCA and averaging the two sets. For visualization, I tried a few different things, including more PCA, PCA across partitions of the dimensions, or various averages. More than ever before, I found the normalization part extremely important and volatile. I suspect that may be because the fine-tuned semantic embeddings are perhaps a little strange.
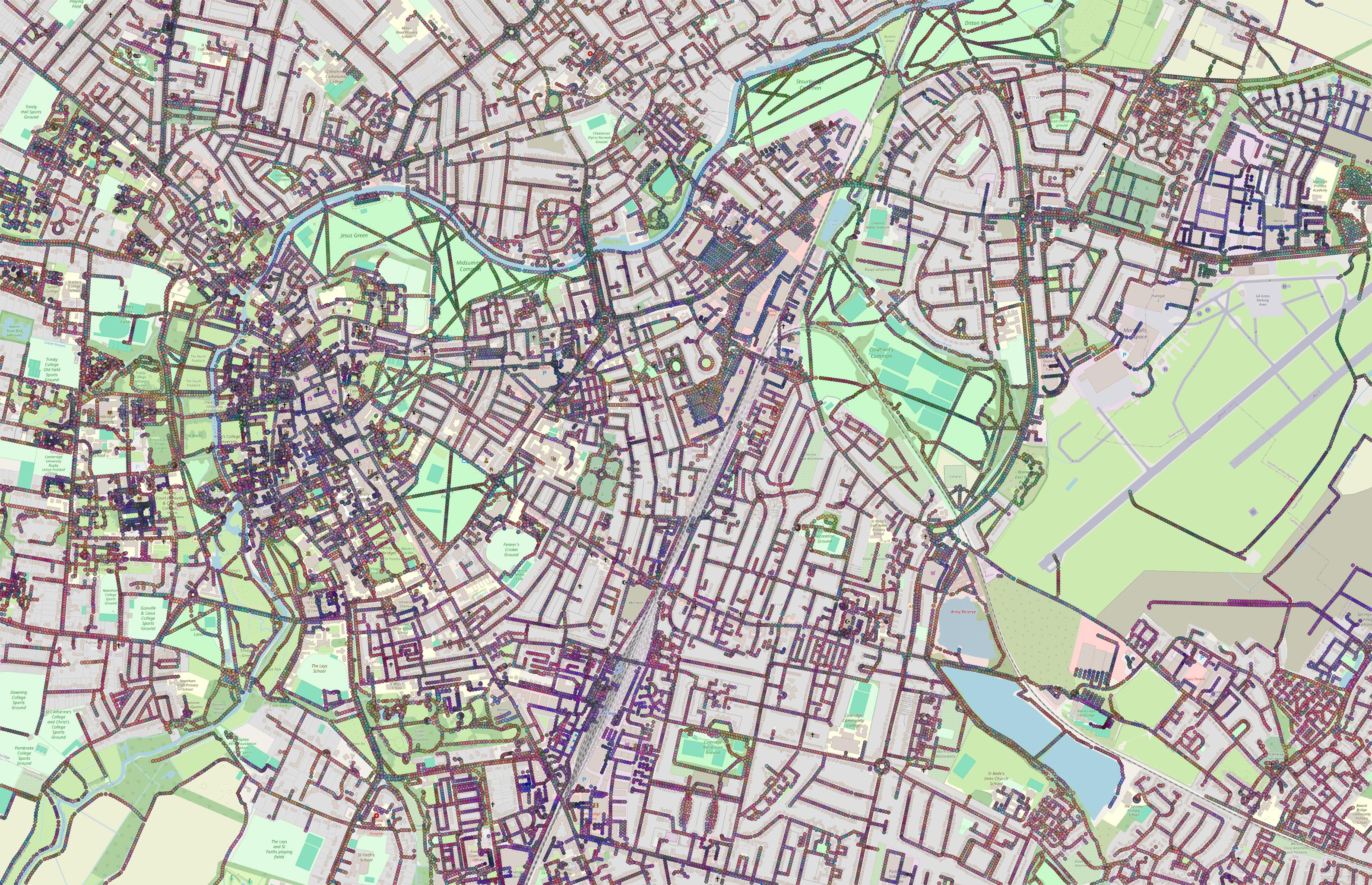
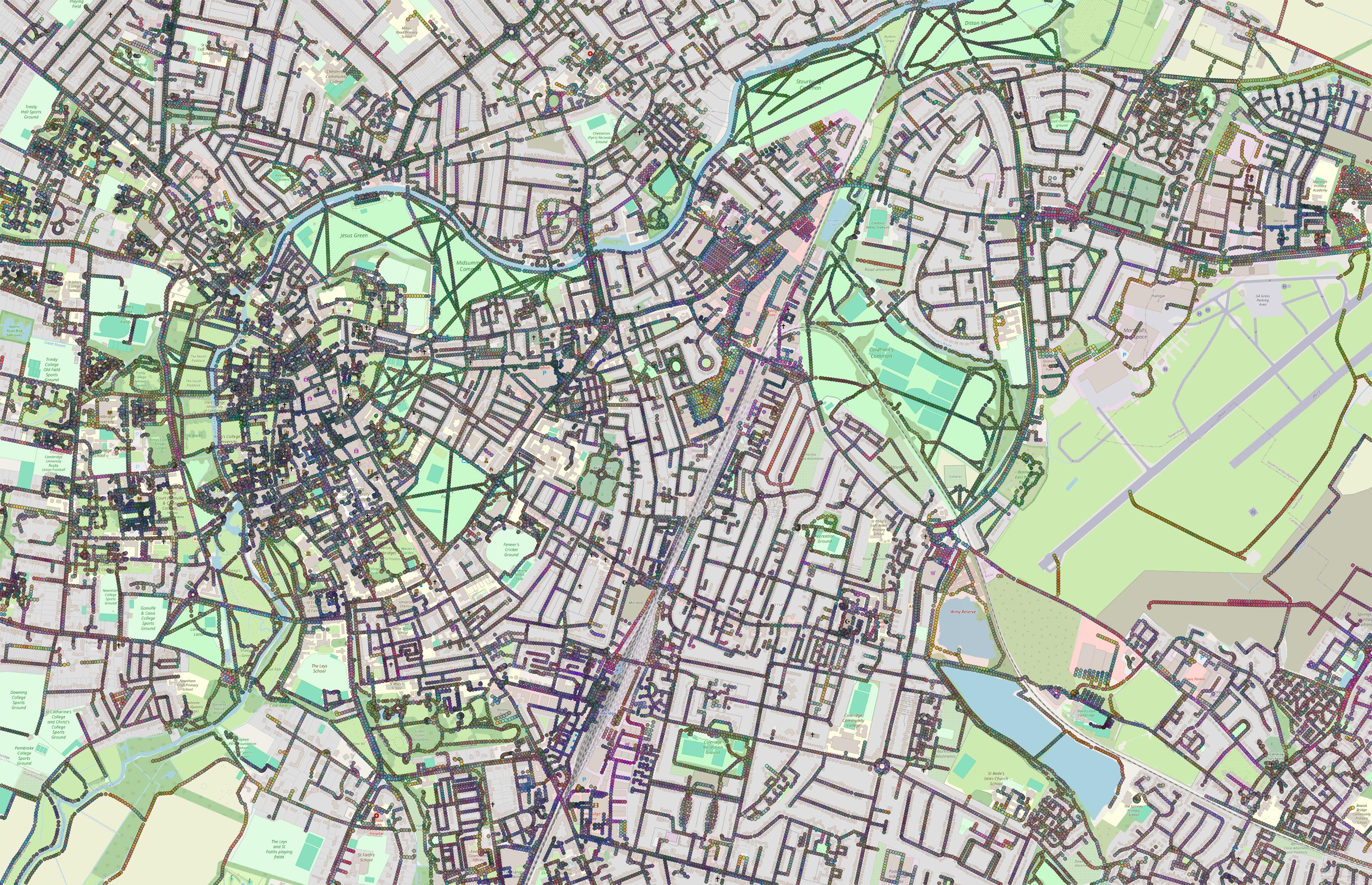
The next important experiment was trying to learn projection heads into a 256-dimensional space, and then taking an average.
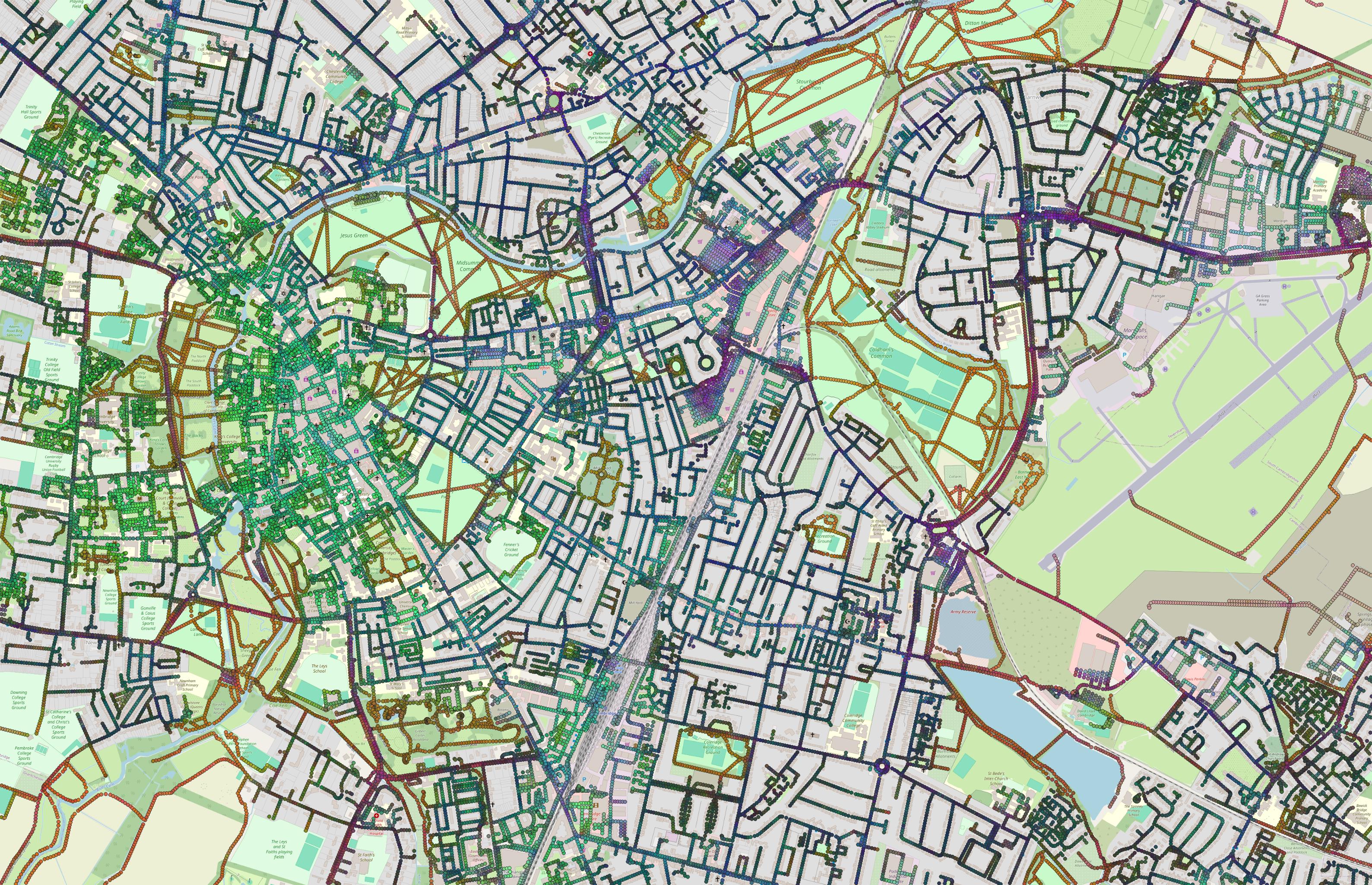
Following up on this experiment, I also trained a quick regression model to actually classify walkability scores on a small-ish subset of labels generated by my old walkability assessment framework.
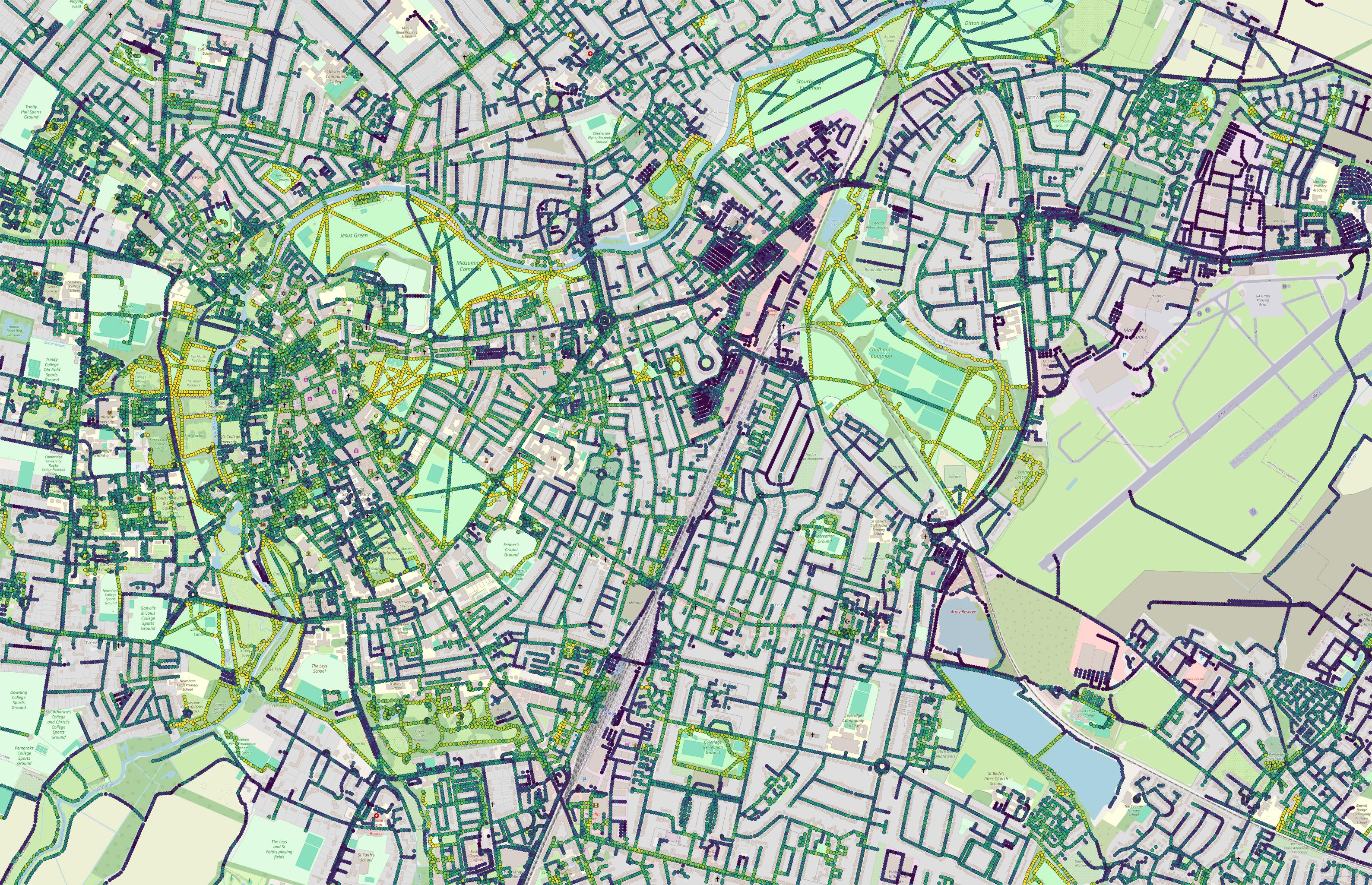
Next week
Next week, I’m very keen to continue exploring the options in combining TESSERA with the semantically-based embeddings. I may also try improving the bramble classification by providing more negative examples, manually picked to tackle the model’s incorrect classifications.