Summer Week 8: more h3, more fusing
Categories:EnvironmentAI/MLFoundationalMLWalkability
This week
was dedicated to generating H3 grids (viz. last week), figuring out ways to fit them on OSM data, creating grids for the path-finding problem, and also trying to figure out fusing, and using TESSERA for walkability assessment.
Grid creation
Expanding on last weeks work, I did some more not-that-interesting work on generating the walkability grid, reflecting on geospatial features from OSM. By this, I mean getting all areas that are clearly not walkable (buildings, water surfaces) and barriers (fences), and filtering the h3 grid accordingly.

There isn’t much interesting to say about this I don’t think, the only problem is that even though this is the highest resolution, there still may be some loss & detecting intersections between the features of interest and the h3 hexagons takes forever (even on such a small area), and so switching to the highest resolution would be very impractical.
Using TESSERA-only for walkability assessment
Since the plan was to expand beyond OSM segments for assessing walkability, trying to use TESSERA for assessing the walkability was an obvious option. However, I haven’t been quite sure how to get the labels necessary for such task. My first approach has been to build a pipeline for sampling diverse points from OSM with interesting descriptions, and then using LLMs running on Ollama to provide some approximate “walkability” estimates. I know this kind of approach isn’t great, but it has worked quite well for me before. Then, I trained a variety of models to try to infer walkability from TESSERA’s embeddings.
Generally, across a few different task, and working with both TESSERA and the semantic embeddings, random forest has seemed like the best algorithm in these settings. Obviously, there’s probably plenty of space for improvement.

I also finally somewhat unified a pipeline that combines the TESSERA embeddings with the semantic embeddings (with trained fusion heads), and uses a variety of models (once again random forest seems random forest is the best) to calculate scores.
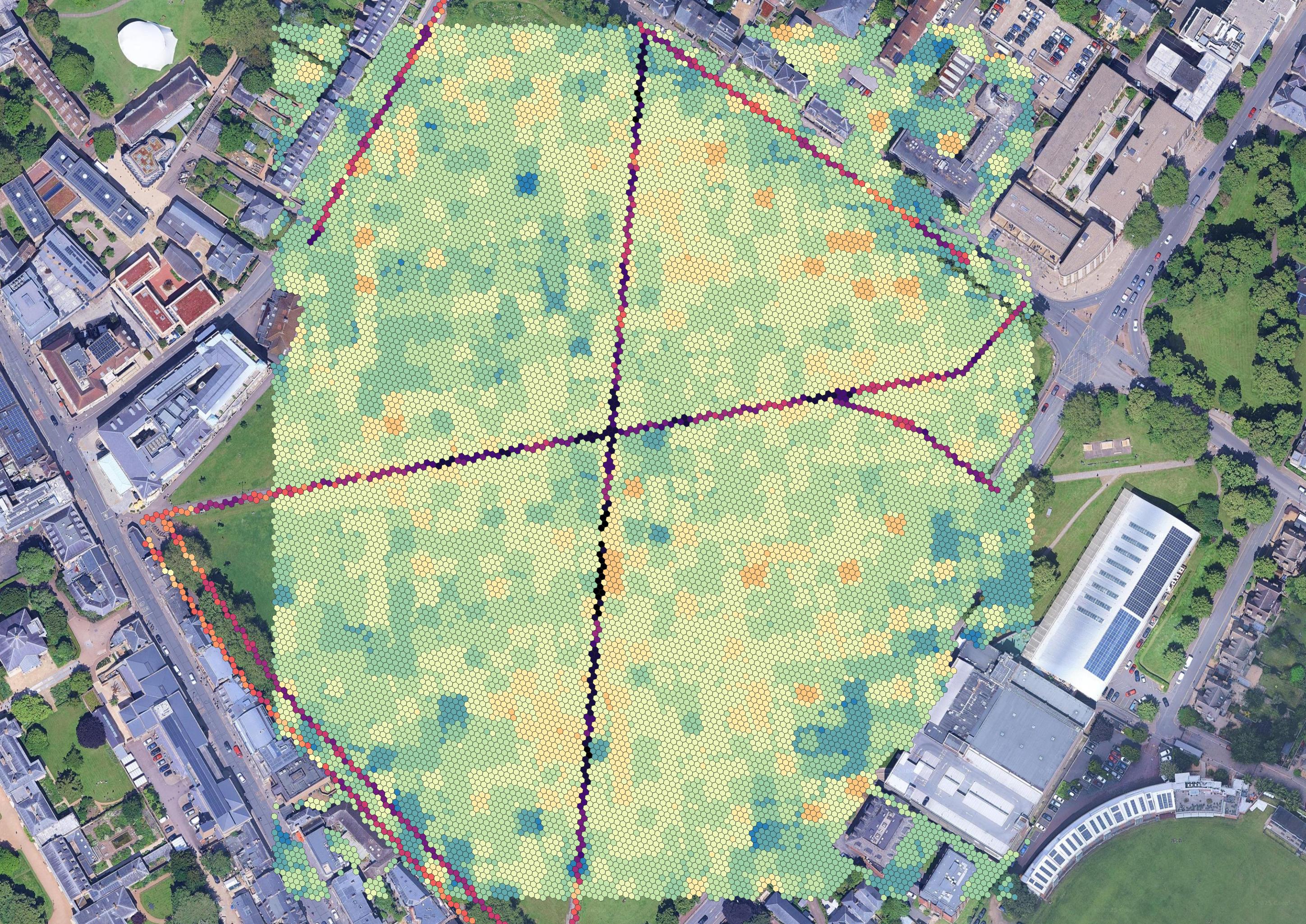
Furthermore, I have been playing around a bit with analyzing the impacts of certain data components on the calculated walkability estimates. For instance, I tried to get a better idea about the (negative) impact of “bicycle path”, which I have observed/suspected in the original anchor based approach. However, it seems the ablations with the currently used regression models are a bit less predictable, and maybe the impact of these individual elements also diminishes during the fusion. That’s certainly not right, and also needs to be improved.
A*
Finally, I have a somewhat working grid A*, which tries to find a path between two hexagons on the grid. This, of course, is complicated by the two contrasting sets of evaluations, that may prevent desired transitions between segments and non-segments = more work on that is to be done too.